Opt Out Scores
Last updated: September 17, 2025
What is an Opt-Out Score?
Every day users use our platform to send and receive messages, but sometimes sifting through the incoming messages can be tough and time consuming. In response, we have developed a model that assigns labels to incoming messages based on the content to help sort your inbox and surface the most important replies.
To do this, we have trained a language model that classifies messages as they’re received and assigns likelihood scores. Currently the model rates the likelihood that a given response is an opt-out attempt, even if the respondent doesn’t use an opt-out keyword. Each message is scored on a scale from 0 to 1, with one being the highest confidence.
How can I use this?
You can find this in your inbox. Instead of exporting your incoming messages and searching for keywords in a spreadsheet, you can utilize our scoring system to filter the incoming messages right in Switchboard!
Open up the “Edit Filters” button, and scroll down on the menu till you find our Opt-Out scores:
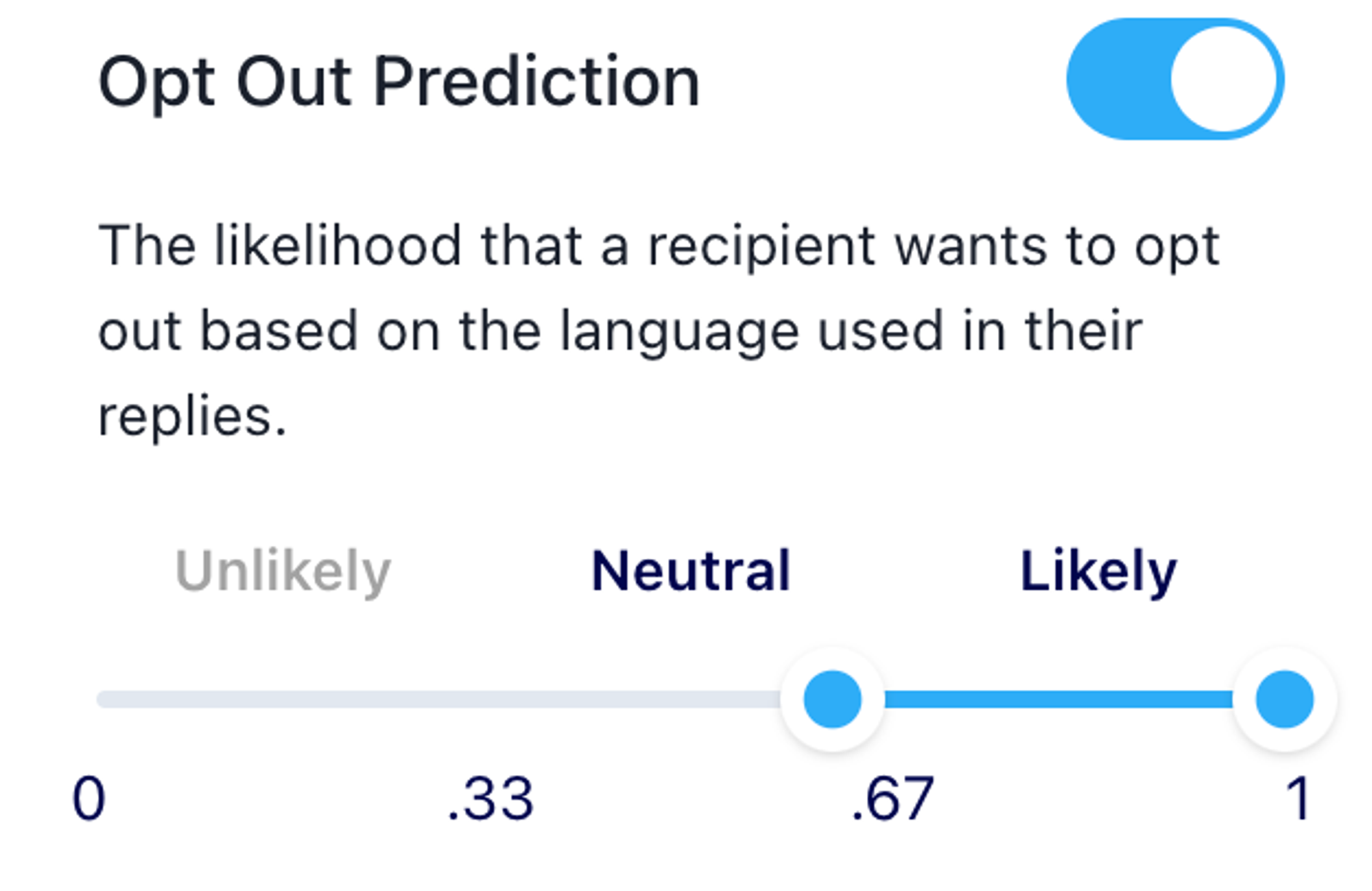
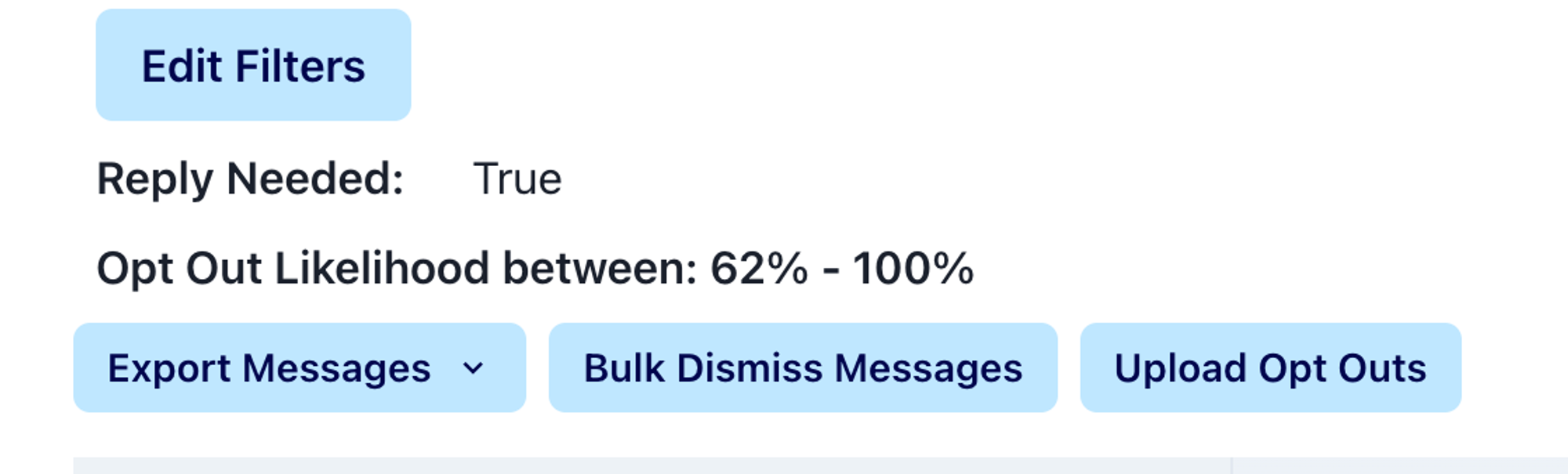
The inbox will only show messages that are labeled with the scores you indicate. You can see exactly your range of scores above the inbox, for example:
About Our Model:
Like any model, the classification this model performs will not be perfect. Despite being accurate on average, it will make mistakes. Please feel free to ask questions about scores and we will monitor the model’s performance over time.
Along with acute problems with modeling, some general limitations also apply to language models like this one:
The model may struggle with understanding the context and nuances of certain words or phrases, especially those with multiple meanings or those used sarcastically.
It may not accurately classify text that contains spelling or grammatical errors, or unexpected sentence structures.
Finally, since it was trained primary on english text, it may not handle languages other than the one it was trained on.
Performance
During our model training, we perform validation of the model’s performance. Scores can give a general sense of the quality of a model but are not conclusive because they are summaries of the model over all.
Those scores, and brief explanations, can be found here:
The model had an evaluation loss of
0.2, which indicates the model's error rate. A lower value suggests a better model.We use the F1 Score of a model to represent the accuracy of the model in terms of both precision and recall. The model scored
0.8where1is the best possible score.The model scores
0.9on the AUC ROC.This is a measure of the model's ability to distinguish between classes, with1indicating perfect classification.Finally, the model correctly predicted the outcome 85% of the time in our testing data.
Training Details
To train our model, we first start with Google’s open-source BERT model trained on Wikipedia data and a corpus of book transcripts. We then fine-tuned this model for our specific use-case by training it on hand-coded examples of messages that clients might receive.
Citation
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRR, abs/1810.04805. Retrieved from http://arxiv.org/abs/1810.0480